Introduction
Integration and batch correction methods have become a popular component in the bioinformatic workflows for scRNA-Seq data analysis, whilst the integration results (mostly corrected PCs or less commonly corrected read counts) are rarely validated or evaluated with an objective metric.
To assess the correctness of integration (i.e. whether cells belonging to the same population are gathered and ones belonging to different populations stay separate after integration), the existing evaluation metrics require the existence of ground truth for cell population annotations.
CIDER provides a ground-truth-free approach to evaluate the integration results. This vignette focuses how showing the process using the example data of dendritic cells.
Load dendritic data
The example data can be downloaded from https://figshare.com/s/d5474749ca8c711cc205. This dataset contains 26593 genes and 564 cells from two batches.
table(dendritic$Batch)
#>
#> Batch1 Batch2
#> 281 283Perform integration
First an integration method\(^1\) is
applied on the dendritic data. You can apply other integration methods
to the your data, as long as the correct PCs are stored in your Seurat
object, i.e. Reductions(seu.integrated, "pca") or
seu.integrated@reductions$pca.
seu.list <- SplitObject(dendritic, split.by = "Batch")
for (i in 1:length(seu.list)) {
seu.list[[i]] <- NormalizeData(seu.list[[i]], verbose = FALSE)
seu.list[[i]] <- FindVariableFeatures(seu.list[[i]],
selection.method = "vst",
nfeatures = 1000, verbose = FALSE)
}
seu.anchors <- FindIntegrationAnchors(object.list = seu.list,
dims = 1:15, verbose = FALSE)
seu.integrated <- IntegrateData(anchorset = seu.anchors,
dims = 1:15, verbose = FALSE)
DefaultAssay(seu.integrated) <- "integrated"
seu.integrated <- ScaleData(seu.integrated, verbose = FALSE)
seu.integrated <- RunPCA(seu.integrated, verbose = FALSE)
seu.integrated <- RunTSNE(seu.integrated, reduction = "pca", dims = 1:5)
seu.integrated@reductions$pca
#> A dimensional reduction object with key PC_
#> Number of dimensions: 50
#> Projected dimensional reduction calculated: FALSE
#> Jackstraw run: FALSE
#> Computed using assay: integratedClear the intermediate outcome.
Evaluate by CIDER
Calculate similarity and p values (essential)
CIDER evaluates integration results in three steps:
- Clustering based on the corrected PCs (
hdbscan.seurat). This step uses HDBSCAN, which is a density-based clustering algorithm\(^2\). The clustering results are stored inseu.integrated$dbscan_cluster. Clusters are further divided into batch-specific clusters by concatenating dbscan_cluster and batch, stored inseu.integrated$initial_cluster. - Compute IDER-based similarity matrix (
getIDEr) among the batch-specific initial clusters. If multiple CPUs are availble, you can setuse.parallel = TRUEandn.coresto the number of available cores to speed it up. - Assign the similarity and estimate empirical p values
(
estimateProb) for the correctness of integration. High similarity values and low p values indicate that the cell are similar to the surrounding cells and likely integrated correctly.
seu.integrated <- hdbscan.seurat(seu.integrated)
ider <- getIDEr(seu.integrated, use.parallel = FALSE, verbose = FALSE)
seu.integrated <- estimateProb(seu.integrated, ider)Evaluation scores
The evaluation scores can be viewed by the scatterPlot
as below. As shown cells with dbscan_cluster of 2 and 3 have low
regional similarity and high empirical p values, suggesting that they
can be incorrectly integrated.
p1 <- scatterPlot(seu.integrated, "tsne", "dbscan_cluster")
p2 <- scatterPlot(seu.integrated, "tsne", colour.by = "similarity") + labs(fill = "Similarity")
p3 <- scatterPlot(seu.integrated, "tsne", colour.by = "pvalue") + labs(fill = "Prob of \nrejection")
plot_grid(p1,p2,p3, ncol = 3)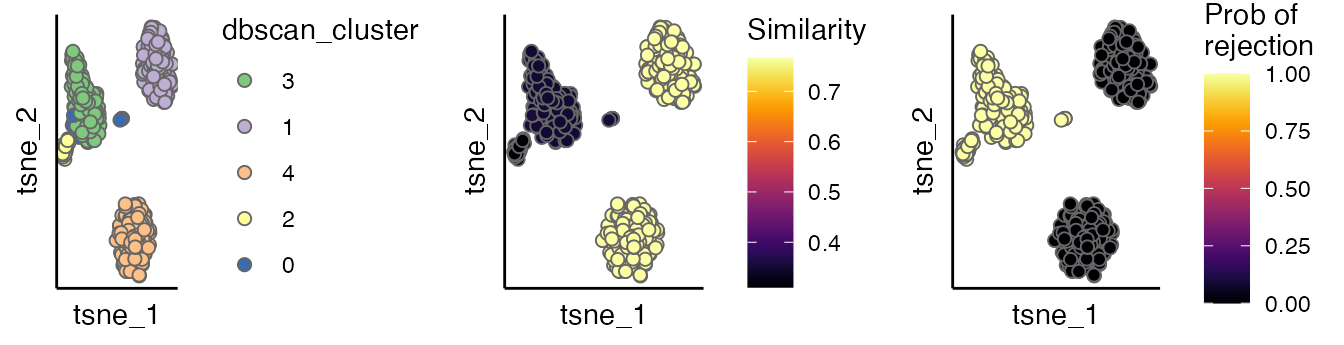
The IDER-based similarity matrix
To have more insight, we can view the IDER-based similarity matrix by
functions plotNetwork or plotHeatmap. Both of
them require the input of a Seurat object and the output of
getIDEr. In this example, 1_Batch1 and 1_Batch2 as well as
4_Batch1 and 4_Batch2 have high similarity.
plotNetwork generates a graph where vertexes are initial
clusters and edge widths are similarity values. The parameter
weight.factor controls the scale of edge widths; larger
weight.factor will give bolder edges proportionally.
plotNetwork(seu.integrated, ider, weight.factor = 3)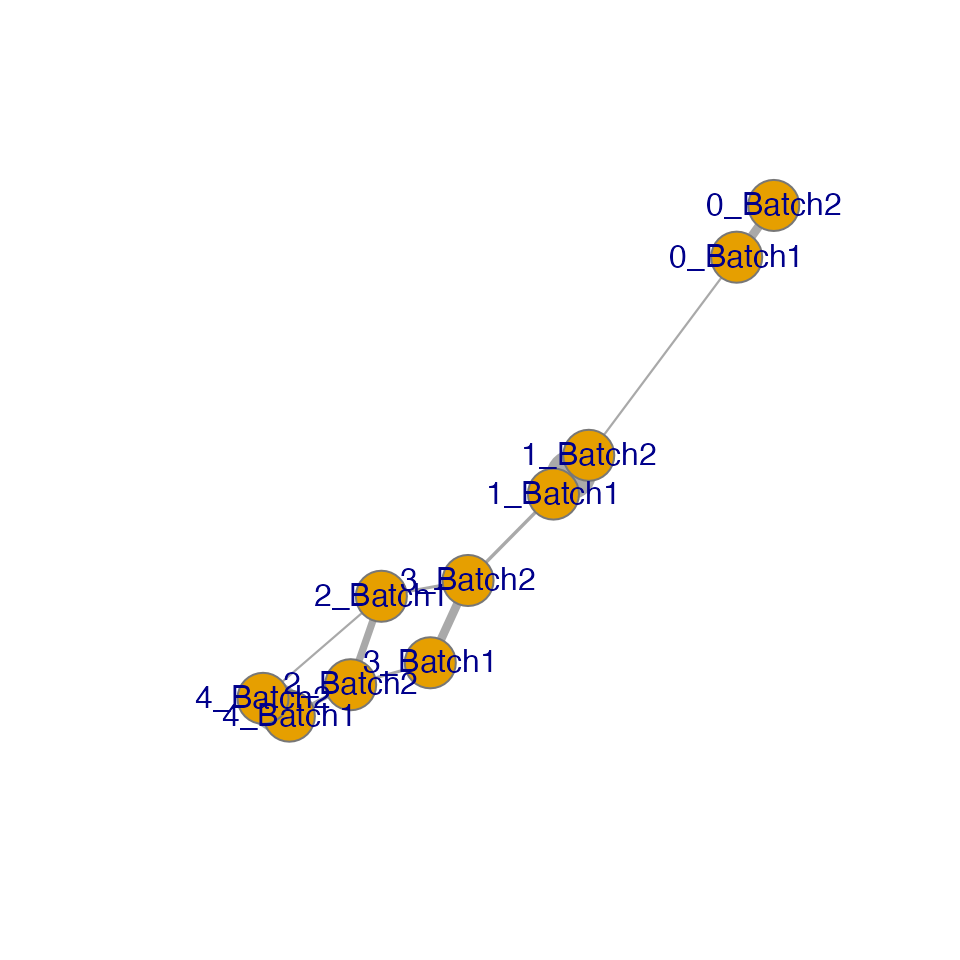
#> IGRAPH 6a879f8 UNW- 10 11 --
#> + attr: name (v/c), frame.color (v/c), size (v/n), label.family (v/c),
#> | weight (e/n), width (e/n)
#> + edges from 6a879f8 (vertex names):
#> [1] 4_Batch1--4_Batch2 4_Batch1--2_Batch2 2_Batch1--4_Batch2 2_Batch1--2_Batch2
#> [5] 2_Batch1--3_Batch2 0_Batch1--0_Batch2 0_Batch1--1_Batch2 1_Batch1--1_Batch2
#> [9] 1_Batch1--3_Batch2 3_Batch1--2_Batch2 3_Batch1--3_Batch2plotHeatmap generates a heatmap where each cell is
coloured and labeled by the similarity values.
plotHeatmap(seu.integrated, ider)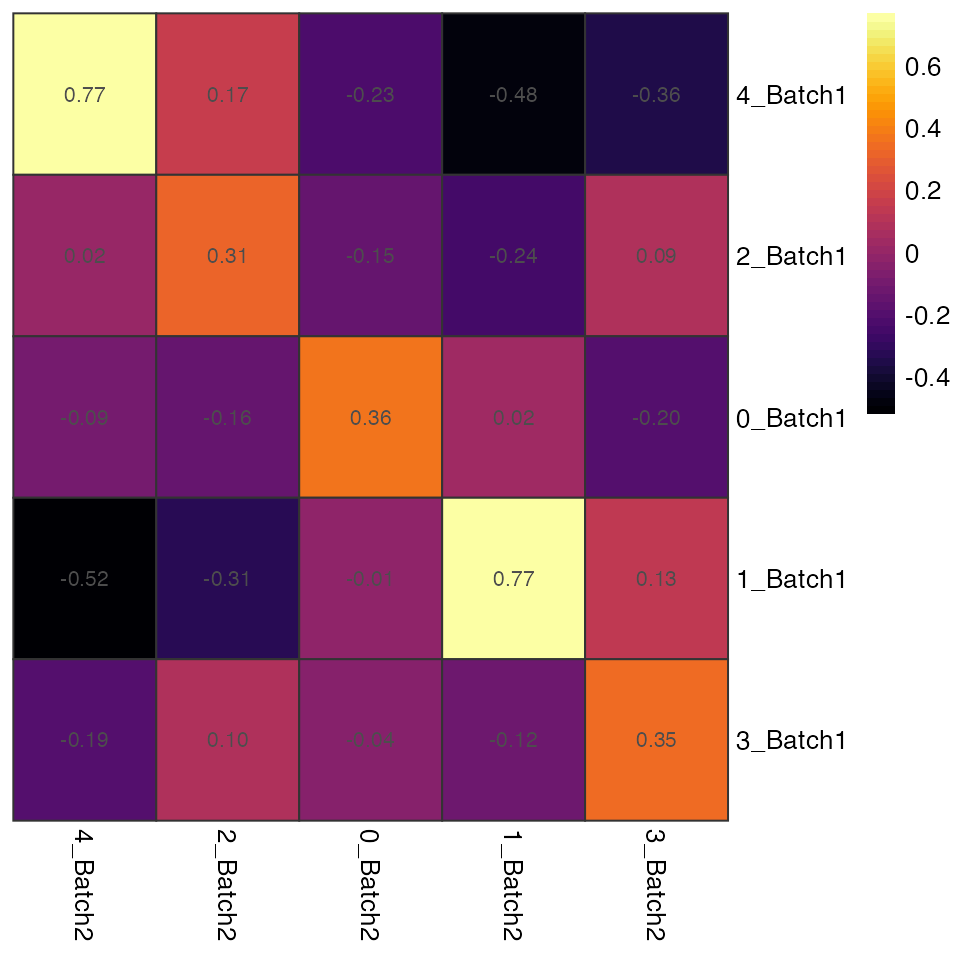
Refering to ground-truth annotation
So far the evaluation have completed and CIDER has not used the ground truth at all!
Let’s peep at the ground truth before the closure of this vignette. As shown in the figure below, the clusters having low IDER-based similarity and high p values actually have at least two popuplations (CD1C and CD141), verifying that CIDER spots the wrongly integrated cells.
scatterPlot(seu.integrated, "tsne", colour.by = "Group") + labs(fill = "Group\n (ground truth)")
Technical
sessionInfo()
#> R version 4.1.2 (2021-11-01)
#> Platform: x86_64-apple-darwin17.0 (64-bit)
#> Running under: macOS Big Sur 10.16
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ggplot2_3.4.2 cowplot_1.1.1 SeuratObject_4.0.4 Seurat_4.1.0
#> [5] CIDER_0.99.1
#>
#> loaded via a namespace (and not attached):
#> [1] systemfonts_1.0.2 plyr_1.8.6 igraph_1.2.8
#> [4] lazyeval_0.2.2 splines_4.1.2 listenv_0.8.0
#> [7] scattermore_0.7 digest_0.6.28 foreach_1.5.1
#> [10] htmltools_0.5.2 viridis_0.6.2 fansi_0.5.0
#> [13] magrittr_2.0.1 memoise_2.0.0 tensor_1.5
#> [16] cluster_2.1.2 doParallel_1.0.16 ROCR_1.0-11
#> [19] limma_3.50.0 globals_0.16.1 matrixStats_0.61.0
#> [22] pkgdown_2.0.7 spatstat.sparse_2.0-0 colorspace_2.0-2
#> [25] ggrepel_0.9.3 textshaping_0.3.6 xfun_0.28
#> [28] dplyr_1.1.2 crayon_1.5.2 jsonlite_1.7.2
#> [31] spatstat.data_2.1-0 survival_3.2-13 zoo_1.8-9
#> [34] iterators_1.0.13 glue_1.6.2 polyclip_1.10-0
#> [37] gtable_0.3.0 leiden_0.3.9 kernlab_0.9-29
#> [40] future.apply_1.8.1 abind_1.4-5 scales_1.2.1
#> [43] pheatmap_1.0.12 DBI_1.1.1 edgeR_3.36.0
#> [46] miniUI_0.1.1.1 Rcpp_1.0.7 viridisLite_0.4.0
#> [49] xtable_1.8-4 reticulate_1.22 spatstat.core_2.3-1
#> [52] htmlwidgets_1.5.4 httr_1.4.2 RColorBrewer_1.1-2
#> [55] ellipsis_0.3.2 ica_1.0-2 pkgconfig_2.0.3
#> [58] farver_2.1.0 sass_0.4.0 uwot_0.1.10
#> [61] deldir_1.0-6 locfit_1.5-9.4 utf8_1.2.2
#> [64] labeling_0.4.2 tidyselect_1.2.0 rlang_1.1.1
#> [67] reshape2_1.4.4 later_1.3.0 munsell_0.5.0
#> [70] tools_4.1.2 cachem_1.0.6 cli_3.4.1
#> [73] dbscan_1.1-8 generics_0.1.1 ggridges_0.5.3
#> [76] evaluate_0.14 stringr_1.5.0 fastmap_1.1.0
#> [79] yaml_2.2.1 ragg_1.1.3 goftest_1.2-3
#> [82] knitr_1.36 fs_1.5.0 fitdistrplus_1.1-6
#> [85] purrr_1.0.1 RANN_2.6.1 pbapply_1.5-0
#> [88] future_1.28.0 nlme_3.1-153 mime_0.12
#> [91] compiler_4.1.2 rstudioapi_0.13 plotly_4.10.0
#> [94] png_0.1-7 spatstat.utils_2.2-0 tibble_3.2.1
#> [97] bslib_0.3.1 stringi_1.7.5 highr_0.9
#> [100] desc_1.4.0 lattice_0.20-45 Matrix_1.3-4
#> [103] vctrs_0.6.2 pillar_1.9.0 lifecycle_1.0.3
#> [106] spatstat.geom_2.4-0 lmtest_0.9-39 jquerylib_0.1.4
#> [109] RcppAnnoy_0.0.19 data.table_1.14.2 irlba_2.3.3
#> [112] httpuv_1.6.3 patchwork_1.1.1 R6_2.5.1
#> [115] promises_1.2.0.1 KernSmooth_2.23-20 gridExtra_2.3
#> [118] parallelly_1.32.1 codetools_0.2-18 MASS_7.3-54
#> [121] rprojroot_2.0.2 withr_2.5.0 sctransform_0.3.3
#> [124] mgcv_1.8-38 parallel_4.1.2 grid_4.1.2
#> [127] rpart_4.1-15 tidyr_1.3.0 rmarkdown_2.11
#> [130] Rtsne_0.15 shiny_1.7.1References
- Stuart and Butler et al. Comprehensive Integration of Single-Cell Data. Cell (2019).
- Campello, Ricardo JGB, Davoud Moulavi, and Jörg Sander. “Density-based clustering based on hierarchical density estimates.” Pacific-Asia conference on knowledge discovery and data mining. Springer, Berlin, Heidelberg, 2013.